October 05, 2011
By Monica Heger
Targeted sequencing of select gene panels may miss druggable mutations in cancer patients when compared to a more comprehensive sequencing strategy that includes RNA-seq, according to several case studies presented at last weekend's Personal Genomes meeting at Cold Spring Harbor Laboratory.
Both Elaine Mardis, co-director of the Genome Institute at Washington University, and Karin Kassahn, a researcher in Sean Grimmond's lab at the University of Queensland in Brisbane, presented case studies of patients for whom druggable mutations were identified via a comprehensive sequencing strategy.
The findings add to the debate about whether targeted sequencing of cancer genes or a more in-depth sequencing approach that includes whole-genome and transcriptome sequencing makes the most sense for clinical sequencing in cancer.
RNA-seq to ID Drug Targets
The Wash U team follows a comprehensive cancer sequencing strategy that includes whole-genome sequencing of tumor and matched normal to 60-fold and 30-fold coverage, respectively, as well as exome sequencing for tumor and normal, tumor transcriptome sequencing, and deep digital sequencing of the tumor sample to verify mutations.
The higher coverage for tumor whole-genome sequencing helps "give us a lot of certainty that what we're seeing somatically is real," Mardis said in a presentation at last weekend's meeting.
Additionally, she added, transcriptome sequencing in particular has helped the team verify mutations, identify targets that they wouldn't have otherwise found, and rule out potentially druggable mutations that turned out not to be expressed in the tumor.
"If we're going to target a mutation, we better make darn sure it's expressed in the tumor genome," she said.
One example Mardis presented was of a patient in her mid-50s with metastatic breast cancer. After an initial biopsy showed that her tumor was ER-negative and HER2-positive, she was treated with paclitaxel and Genentech's Herceptin (trastuzumab). In 2010, however, the disease progressed, metastasizing to her brain, and surgery was performed.
The Wash U team then sequenced tissue from the surgical sample. An initial analysis of the RNA-seq results revealed that only about 40 percent of the mutations in the tumor genome were expressed.
Additionally, the team used the RNA-seq data to identify an amplification of HDAC2, a druggable target. "This is not evidence of a mutation, but evidence of over-expression," she said. The gene is "amplified to almost the same degree as HER2 … and this is a targetable amplification."
Two HDAC inhibitors — Merck's Zolinza (vorinostat) and Celgene's Istodax (romidepsin) — have been approved for use in cutaneous T-cell lymphoma, and several are in clinical trials for various other cancers.
While the patient is currently on a combination drug regimen that has stabilized her disease, the identification of the HDAC2 amplification will most likely guide future treatment, Mardis added.
The Wash U team found that including transcriptome sequencing also helped guide treatment for a patient with acute lymphocytic leukemia. The patient, whose leukemia developed when he was in his 20s, initially received a bone marrow transplant from a sibling, but then relapsed.
Following the relapse, he was given induction therapy and appeared to achieve remission. The Wash U team, which had sequenced the patient's tumor genome on his initial diagnosis, sequenced it again to see if there was any residual disease that couldn't be identified with other methods. The team identified the two populations of tumor subclones that were characteristic of his initial disease and likely led to his relapse. Those subclones indicated that even if he received a second transplant, "he would still be at risk for disease," Mardis said.
Looking at the whole-genome sequencing data, the team identified 91 somatic tier 1 SNVs. Transcriptome sequencing confirmed that 42 of them were expressed in the tumor tissue. However, "none were obvious targetable mutations, so we didn't know what to do."
A close look at the RNA-seq data revealed "unusual FLT3 expression, at extraordinarily high levels," Mardis said.
Two weeks ago, the patient was prescribed Pfizer's Sutent (sunitinib), which targets FLT3 among several other kinases. Three days following the initial Sutent treatment, a blood test indicated marked improvement.
The plan now, said Mardis, is to keep the patient on Sutent for three weeks and then re-evaluate his remission status. If remission is complete, a bone marrow donor has already been identified and he will receive a transplant.
Both cases illustrate the need for comprehensive sequencing, said Mardis.
Identifying Pathways
A team from the University of Queensland in Brisbane, Australia, has also found that a comprehensive sequencing approach helps to identify druggable mutations. Researchers in Sean Grimmond's lab at the Queensland Center for Medical Genomics, including Kassahn, have been sequencing the exomes of pancreatic cancer patients as part of its contribution to the International Cancer Genome Consortium.
Additionally, as part of a collaboration with Andrew Biankin's group at the Garvan Institute, the team is doing more comprehensive sequencing on select samples to try and determine how clinical sequencing could be employed on cancer patients. Biankin is also spearheading a clinical trial to use sequencing to guide treatment — the Individualized Molecular Pancreatic Cancer Therapy, or IMPACT, clinical trial — which will use next-gen sequencing to determine second-line treatment for patients.
While cohort genomics — sequencing the exomes or whole genomes of many patients —has the "power to detect recurrence" for projects like the ICGC, a more comprehensive strategy is needed for personal genomics, where the goal is to suggest therapy, Kassahn said.
At the Cold Spring Harbor meeting she presented an example of a patient her team sequenced as part of a pilot to determine the feasibility of sequencing cancer patients.
The woman had been diagnosed with pancreatic cancer at the age of 84. She had surgery and was treated with Eli Lilly's Gemzar (gemcitabine), but became resistant, and passed away 15 months after her initial diagnosis.
Kassahn said the team used an integrated sequencing strategy, performing whole-genome and exome sequencing, RNA-seq, and miRNA-seq on Life Technologies' SOLiD, and methylation array analysis. Additionally, they used the Ion Torrent PGM for amplicon sequencing to verify somatic mutations.
They identified 29 somatic missense and nonsense mutations, only 11 of which were expressed in the tumor. Additionally, they identified 22 regions of homozygosity loss, two indels, 14 interchromosomal events including one fusion transcript, 10 intrachromosomal events, three inversions, and 167 complex rearrangements that they are still verifying.
They identified mutated genes typical of pancreatic cancer — such as TP53, PTEN, and KRAS — as well as some private point mutations.
Making sense of the complex data to try and identify an alternative therapy would not have been possible if the team had just done whole-genome or whole-exome data, Kassahn said. By incorporating the transcriptome sequencing data and methylation data, the team was able to piece together the networks and pathways that were most heavily involved in the cancer, rather than focusing on specific genes.
The network analysis pointed to the DNA replication pathway as the top network. "Three mutations in that network stood out to us," Kassahn said. Two genes are known to be sensitive to mitomycin-C. One of them is part of the BRCA network, while the other is involved in cell survival following DNA damage and has also been seen in other cancers. The third gene also interacts with BRCA, is involved in DNA replications, and is chemosensitive to genotoxic stress.
Based on their analysis, the researchers tested mitocycin-C first in xenograft models of the tumor. The tumor stopped growing and in some replicates, there was a slight reduction, Kassahn said.
"That was exciting and pointed that we identified a useful target," she said.
In this case, however, the patient had already passed away, but Kassahn said the team will apply its lessons learned as part of the IMPACT clinical trial.
In particular, Kassahn said the integrated analysis, which included "overlaying the copy number changes, somatic mutations, expression data, and methylation status, … made us confident that we were on the right track."
The case also illustrated the difference between sequencing cohorts to identify common mutations in cancer and sequencing individual patients to identify possible therapies.
"A specific patient doesn't want to know what's common," Kassahn said. And in fact, the targetable mutations identified in this patient have not been seen in the 70 exomes the team has sequenced as part of the ICGC project, she added.
Targeted vs. Comprehensive Sequencing
While other groups, such as the University of Michigan's Center for Translational Pathology, are employing a similar comprehensive sequencing strategy for individual patients (CSN 8/31/2011), targeted sequencing has recently been gaining ground for cancer diagnostics (CSN 8/17/2011).
A number of organizations and companies, including a team at Dana Farber Cancer Institute, the Ontario Institute of Cancer Research, and Foundation Medicine are developing targeted cancer gene panels that will evaluate the mutational status of between about 50 and 200 known cancer genes.
These targeted panels could serve as a lower-cost and quicker method for helping to guide treatment for cancer patients, but Mardis said that they might miss genes that are over-expressed or deleted.
While the number of mutations these panels miss will depend in part on the tumor, she said that her team has estimated that between "20 to 30 percent of what needs to be known to inform treatment won't be captured by a targeted approach."
The debate is still unsettled as to which technique will ultimately prove more effective, and ultimately both models could prove necessary depending on the specific case.
Note: Taken from http://www.genomeweb.com/sequencing/cshl-conference-researchers-highlight-importance-rna-seq-data-guide-cancer-treat
Tuesday, October 18, 2011
Wednesday, April 13, 2011
Next-generation Sequencing (Illumina)

Illumina's $600 million acquisition of Solexa in November 2006 gave the company a head start in the next generation sequencing market.
This post is a brief overview of Solexa's sequencing-by-synthesis chemistry. The sample prep methods used differ slightly from that used in ABI's SOLiD system, but the basic goals are the same: generate large numbers of unique "polonies" (polymerase generated colonies) that can be simultaneously sequenced. These parallel reactions occur on the surface of a "flow cell" (basically a water-tight microscope slide) which provides a large surface area for many thousands of parallel chemical reactions.
Step 1: Sample Preparation
The DNA sample of interest is sheared to appropriate size (average ~800bp) using a compressed air device known as a nebulizer. The ends of the DNA are polished, and two unique adapters are ligated to the fragments. Ligated fragments of the size range of 150-200bp are isolated via gel extraction and amplified using limited cycles of PCR.
Complete detailed protocols for DNA and small RNA library preparation can be found in the documents provided in the attachments to this post. ("dna_libe_prep.pdf" and "rna_libe_small_prep.pdf", respectively). This process is a fairly straightforward multi-step molecular biology process, however there are many pitfalls that can result in skewed results downstream.
Steps 2-6: Cluster Generation by Bridge Amplification
In contrast to the 454 and ABI methods which use a bead-based emulsion PCR to generate "polonies", Illumina utilizes a unique "bridged" amplification reaction that occurs on the surface of the flow cell.
The flow cell surface is coated with single stranded oligonucleotides that correspond to the sequences of the adapters ligated during the sample preparation stage. Single-stranded, adapter-ligated fragments are bound to the surface of the flow cell exposed to reagents for polyermase-based extension. Priming occurs as the free/distal end of a ligated fragment "bridges" to a complementary oligo on the surface.
Repeated denaturation and extension results in localized amplification of single molecules in millions of unique locations across the flow cell surface. This process occurs in what is referred to as Illumina's "cluster station", an automated flow cell processor.

Steps 7-12: Sequencing by Synthesis
A flow cell containing millions of unique clusters is now loaded into the 1G sequencer for automated cycles of extension and imaging.
The first cycle of sequencing consists first of the incorporation of a single fluorescent nucleotide, followed by high resolution imaging of the entire flow cell. These images represent the data collected for the first base. Any signal above background identifies the physical location of a cluster (or polony), and the fluorescent emission identifies which of the four bases was incorporated at that position.
This cycle is repeated, one base at a time, generating a series of images each representing a single base extension at a specific cluster. Base calls are derived with an algorithm that identifies the emission color over time. At this time reports of useful Illumina reads range from 26-50 bases.

The use of physical location to identify unique reads is a critical concept for all next generation sequencing systems. The density of the reads and the ability to image them without interfering noise is vital to the throughput of a given instrument. Each platform has its own unique issues that determine this number, 454 is limited by the number of wells in their PicoTiterPlate, Illumina is limited by fragment length that can effectively "bridge", and all providers are limited by flow cell real estate.
Source from http://seqanswers.com/forums/showthread.php?t=21... credit to "ECO".
Tuesday, December 14, 2010
Inside Cancer
Cancer in general:
- Cancer is a disease that affects people of nationalities and age groups.
- All cancers start with mutations in one cell.
- There are many types of cancers that can occur in any organ or tissue of he human body which are:
1) Solid tumors (form lumps)
2) Liquid tumors (flow freely in the blood)
- Less than 10% of all cancer mutations are inherited. Usually it arises as a result of environmental factors.
- DNA mutation can produce mutant protein.
- When accumulation of mutant protein produced it will transforms a normal cell into a cancerous one.
- As we age, we accumulate more and more mutations. This explains why cancer incidence increases with age.
- The mutation can cause disruption of cell's growth life cycle, proliferation and death.
Causes of Cancers:
- Causes of cancers can be divided into 3 types according to epidemiologists as stated below:
1) Inherited factors = less than 10%
2) Synthetic chemicals factors (pollution, food additives, etc) = less than 5%
3) Environmental, dietary, cultural, or lifestyle factors = 85%
- As for oral cancer, although it has multifaceted etiology, tobacco use and alcohol consumption are widely considered to be its major risk factors.
- Tobacco use remains the single most important and preventable cause of this disease.
Killers in smoke
- A cigarette smoker inhales over 60 known/suspected cancer-causing agents (carcinogens), including polyaromatic hydrocarbons (PAHs), nitrosamines, and heavy metals.
- Smoke moves with inhaled air down the respiratory tract – from the trachea to the bronchi, and then branching into ever-smaller bronchioles.
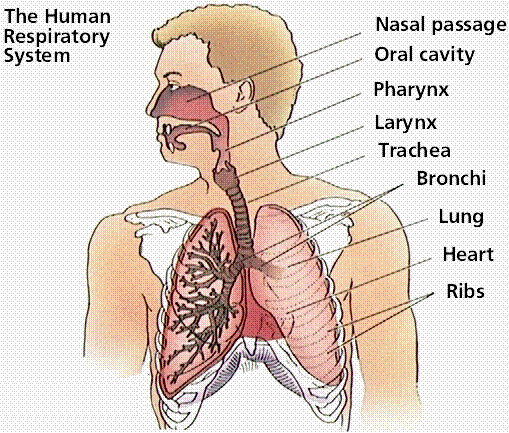
- The bronchioles end in alveoli sacs where nicotine, carbon monoxide, and other gases in cigarette smoke are exchanged with the blood.
- Carcinogens can then enter the cells and cause DNA damage.
- The damaged cells may eventually progress to oral cancer.
- K-ras and p53 are the two genes most frequently mutated in smoking-related cancers.
- One tar component, benzo[a]pyrene, is specifically linked to known mutations in these genes – providing the equivalent of a "smoking gun" at a murder scene.
K-ras
- The protein produced by the K-ras gene is a tumor “activator.”
- Its overactivity contributes to tumor development.
- The K-ras protein resides on the inner side of the cell membrane, where it conducts growth signals from cell-surface receptors to the nucleus.
- This process is called signal transduction.
- Signal transduction begins with the arrival of a growth factor at the cell surface, where it recognizes a specific receptor anchored in the cell membrane. The binding of the growth factor to its receptor conducts a growth signal into the cell interior.
- The K-ras protein accepts the growth signal and, in turn, relays it to other molecules in the cytoplasm. Raf and other signal transducers are protein kinases, which activate other molecules by adding phosphate groups.
- This signaling cascade culminates in the nucleus with the activation of Fos and Jun, two transcription factors that join together to initiate transcription of genes involved in cell replication.
- Mutations in the K-ras gene result in a K-ras protein that is essentially stuck in an “on” position – perpetuating a signaling cascade in the absence of any real signal from a growth factor.
P53
- The p53 protein is a tumor suppressor, its activity helps counter tumor development.
- P53 occupies a “checkpoint” in the cycle of cell division, where it “senses” DNA damage or mutations.
- The cell cycle is composed of four stages:

- During the first Gap Phase (G1) the cell grows and replenishes its resources.
- During S Phase (S) the cell synthesizes DNA in preparation for cell division.
- During the second Gap Phase (G2) the cell synthesizes proteins and other cellular components needed for cell division.
- During Mitosis Phase (M) the cell divides into two daughter cells.
- P53 acts as a checkpoint into the critical Synthesis (S) and Mitosis (M) Phases. After receiving information from DNA repair systems, p53 can signal the cell to stop dividing, allowing time for a mutation to be repaired before it is passed on to daughter cells.
- For example, p53 arrests the cell cycle, allowing time to repair G-T mutations induced by benzo[a]pyrene.
- If the DNA damage is too great to repair, p53 can signal the cell to commit suicide by the process called apoptosis, or programmed cell death.
- Mutations in p53 cause a loss of checkpoint control, allowing mutations and DNA damage to accumulate in a cell lineage.
- Carcinogen connection : The classic mechanism of carcinogenesis is based on the fact that carcinogens, when they are activated, end up causing DNA adducts and DNA damage.
Diagnosis and Treatment:
Tumor profiling (microarrays)
- Based on set of genes one can see big differences between the molecular pattern of these tumors and as these investigators noted, this correlates with the probability with which the disease will progress, within five years of being diagnosed.
- Why is this important? Clearly it shows that despite the fact that these patients have similar pathologies they're molecularly very different.

- This information in the future could allow oncologists to decide whether or not additional therapy, for example chemotherapy, would be required.
- In the case of those patients that had the good prognostic gene expression pattern, would perhaps not require chemotherapy in addition to surgery and therefore they would be spared the devastating side effects of that therapy.
- By understanding the natures of some of the genes that go up in these poor prognosis tumors it might be ultimately possible to design drugs that would specifically target these genes and then treat those cancers in a much more rational way.
Thursday, December 9, 2010
Lists of Software for Bioinformatics: Pathway Analysis Tools
Today I want to share informations related to my research. Might as well as reference for those who are still looking for pathway analysis analysis.
- BIOCARTA : http://www.biocarta.com/
- Cell Illustrator: http://www.gene-networks.com
- Cognia Molecular: http://www.cognia.com
- ExPASy (Expert Protein Analysis System): http://us.expasy.org/tools/pathways/
- GenMAPP: http://www.genmapp.org/
- KEGG: http://www.genome.jp/kegg/
- MetaCore: http://www.genego.com
- Multifactor Dimensionality Reduction (MDR): http://www.epistasis.org/software.html
- PathArt: http://www.jubilantbiosys.com
- PathwayStudio (formerly PathwayAssist): http://www.ariadnegenomics.com
- Pathways Analysis: http://www.ingenuity.com
- Pathway Tools: http://bioinformatics.ai.sri.com/ptools/
- Protein Networker: http://www.PremierBiosoft.com
- Vector Xpression and Vector PathBlazer: http://www.invitrogen.com
I also would like to share this website BioGPS http://biogps.gnf.org/#goto=welcome which I found very interesting and useful for my research. I don't have to go many websites just to get the information I need.
Wednesday, November 24, 2010
Biological Pathways
Today I went to a coffee shop nearby with my housemate Reera Chan and spent almost 5 hours at there just to get different environment and inspiration for my report writing. While google-ing and searching for articles, I have found these interesting questions related to my research which are always questioned on my mind. I was very glad I found it cause it makes me more enthusiast to my work. I want to share it here so that I can just go back and forth if I lost my way later (practically it become my notes hehe..)
What is a biological pathway?
A biological pathway is a series of actions among molecules in a cell that leads to a certain product or a change in a cell. Such a pathway can trigger the assembly of new molecules, such as a fat or protein. Pathways can also turn genes on and off, or spur a cell to move.
How do biological pathways work?
For your body to develop properly and stay healthy, many things must work together at many different levels - from organs to cells to genes.
Cells are constantly receiving cues from both inside and outside the body, which are prompted by such things as injury, infection, stress or even food. To react and adjust to these cues, cells send and receive signals through biological pathways. The molecules that make up biological pathways interact with signals, as well as with each other, to carry out their designated tasks.
Biological pathways can act over short or long distances. For example, some cells send out signals to nearby cells to repair localized damage, such as a scratch on your knee. Other cells produce substances, such as hormones, that travel through your blood to distant target cells.
Biological pathways can also produce small or large outcomes. For example, some pathways subtly affect how the body processes drugs, while others play a major role in how a fertilized egg develops into a baby.
There are many other examples of how biological pathways help our bodies work. The pupil in your eye opens or closes in response to light. If your skin senses that the temperature is rising, your body sweats to cool you down. In fact, without biological pathways, we-and all other living creatures-could not exist.
Still, it's important to keep in mind that biological pathways do not always work properly. When something goes wrong in a pathway, the result can be a disease such as cancer or diabetes.
What are some types of biological pathways?
There are many types of biological pathways. Some of the most common are involved in metabolism, the regulation of genes and the transmission of signals.
Metabolic pathways make possible the chemical reactions that occur in our bodies. An example of a metabolic pathway is the process by which your cells break down food into energy molecules that can be stored for later use. Other metabolic pathways actually help to build molecules.
Gene regulation pathways turn genes on and off. Such action is vital because genes produce proteins, which are the key components needed to carry out nearly every task in our bodies. Proteins make up our muscles and organs, help our bodies move and defend us against germs.
Signal transduction pathways move a signal from a cell's exterior to its interior. Different cells are able to receive specific signals through structures on their surface, called receptors. After interacting with a receptor, the signal travels through the cell where its message is transmitted by specialized proteins that trigger a specific action in the cell. For example, a chemical signal from outside the cell might be turned into a protein signal inside the cell. In turn, that protein signal may be converted into a signal that prompts the cell to move.
What is a biological network?
Researchers are learning that biological pathways are far more complicated than once thought. Most pathways do not start at point A and end at point B. In fact, many pathways have no real boundaries, and they often work together to accomplish tasks. When multiple biological pathways interact with each other, it is called a biological network.
How do researchers find biological pathways?
Researchers have discovered many important biological pathways through laboratory studies of cultured cells, bacteria, fruit flies, mice and other organisms. Many of the pathways identified in these model systems are the same or have similar counterparts in humans.
Still, many biological pathways remain to be found. It will take years of research to identify and understand the complex connections among all of the molecules in all biological pathways, as well as to understand how these pathways work together.
What can biological pathways tell us about disease?
Researchers are able to learn a lot about human disease from studying biological pathways. Identifying what genes, proteins and other molecules are involved in a biological pathway can provide clues about what goes wrong when a disease strikes.
For example, researchers may compare certain biological pathways in a healthy person to the same pathways in a person with a disease to discover the roots of the disorder. Keep in mind that problems in any number of steps along a biological pathway can often lead to the same disease.
How can biological pathway information improve health?
Finding out what pathway is involved in a disease-and identifying which step of the pathway is affected in each patient-may lead to more personalized strategies for diagnosing, treating and preventing disease.
Researchers currently are using information about biological pathways to develop new and better drugs. It likely will take some time before we routinely see drugs that are specifically designed using the pathway approach. However, doctors are already beginning to use pathway information to more effectively choose and combine existing drugs.
Why are cancer researchers excited about biological pathways?
Take the case of cancer. Until recently, many had hoped that most types of cancers were driven by a single genetic error and could be treated by designing drugs to target those specific errors. Much of that hope was based on the success of imatinib (Gleevec), a drug that was specifically designed to treat a blood cancer called chronic myeloid leukemia (CML). CML occurs because of a single genetic glitch that leads to the production of a defective protein that spurs uncontrolled cell growth. Gleevec binds to that protein, stopping its activity and producing dramatic results in many CML patients.
Unfortunately, the one-target, one-drug approach has not held up for most other types of cancer. Recent projects that deciphered the genomes of cancer cells have found an array of different genetic mutations that can lead to the same cancer in different patients. Then, based on the genetic profile of their particular tumor, patients could receive the drug or drug combination that is most likely to work for them.
The complexity of the findings appears daunting. Instead of attempting to discover ways to attack one well-defined genetic enemy, researchers now faced the prospect of fighting lots of little enemies. Fortunately, this complex view can be simplified by looking at which biological pathways are disrupted by the genetic mutations. Rather than designing dozens of drugs to target dozens of mutations, drug developers could focus their attentions on just two or three biological pathways. Patients could then receive the one or two drugs most likely to work for them based on the pathways affected in their particular tumors.
You might think of it like this: Imagine a thousand people from all across the United States travelling towards the front door of a single building in Chicago. How would you keep all of these people from entering the building?
If you had limitless resources, you could hire workers to go out and stop each person as he or she drove down the highway, arrived at the train station or waited at the airport. That would be the one-target, one-drug approach.
But if you wanted to save a lot of time and money, you could just block the door to the building. That is the pathway-based strategy that many researchers are now pursuing to design drugs for cancer and other common diseases.
Source: National Human Genome Research Institute, National Institutes of Health.
Tuesday, November 23, 2010
Citation from "Al-Quran's Best Health Secret"
Dangers of smoking:
Cigarette contains more than two hundred and toxic substances. Among the most dangerous is nicotine, tar and carbon monoxide. Nicotine is the addictive substance that affects nerve cells in the brain to release dopamine (cell / neurotransmitters that create a feeling of comfort and pleasure when smoking).Therefore, smokers become addicted.
There are two types of smokers; active smokers and passive smokers. Active smokers are those who live on smoking while passive smokers are those who inhale tobacco smoke. Typically, passive smokers have a risk of health disorders twice as large as those of active smokers inhale cigarette of side stream smoke and main stream smoke.
Side-stream smoke = smoke from cigarettes is not go through the filtering and has a high concentration of poisonous substances.
Main-stream smoke = smoke inhaled by smokers, and have gone through filtering.
By looking at the adverse effects of smoking both in terms of health or economic, then of course we as Muslims must refrain from smoking because the harm is greater benefit from boiling. In addition, there is nothing in Islam to smoke, both in the Qur'an or Hadith. Actually, smoking is a culture of Indian tribes as veneration of the god Shiva. Hence, there is the view that smoking is not only illegal, but also musyrik (disobey god's law). The reason is there is no such teaching in Islam and usually smokers are more likely to prioritize cigarette smokes because they will do everything to smoke. For smokers, smoking is everything, more important than anything else.
Fasting:
Islam requires the fasting month of Ramadhan. In terms of health, the rationale of fasting is vital . What would happen if no one's fast? Digestive organs will work all the time without a break and so that the cells will quickly die and degradation. As a result, rapid aging will follow. Spiritually, those who fast will feel calm. It is very influential on the harmonization of energy cells so stress hormones under control.
Monday, July 26, 2010
Pathway analysis: Data analysis and exploration of cancer transcriptome
How to analyze such analysis?? I keep wondering what is the best methodology to uncertain answer from the vast amount of high-throughput data. A lot of questions need to be answered. Finally, I've found a slide presentation that have similar things that I've wanted to figure out. It captivates my reading that those questions perhaps could help me to investigate more and answer my questions. Those questions that captured me are:
1. What regulatory relationships exist between the genes or protein in my dataset?
- Networks
2. Which biological and disease processes are most relevant to my genes of interest?
-Functional analysis
3. Which well-characterized cell signaling and metabolic pathways are most relevant to my experimental data?
-Canonical pathways
4. Which functions and pathways are regulated at different times, dose, disease state, array vs proteomic studies?
-Comparison
5. Search for genes associated with disease, cellular phenotypes. Create lists of genes to analyze.
-Search
6. Edit pathways, build molecular models by connecting genes of interest, identifying regulatory paths between genes
-My pathways
Hopefully from those questions, it would assist me to look into the insight of biological mechanisms in the cancer progressions. Now I'm trying to focus my study and see what happen next.. till then..
Subscribe to:
Posts (Atom)